
【Spark】Spark Streaming中复杂的多流Join方案的一个实现
问题:多个不同流根据一定规则join的问题(例如:网约车中订单发单流与接单流join问题)
问题
描述:多个不同流根据一定规则join的问题(例如:网约车中订单发单流与接单流join问题)
特点:
- 不同流需要join的数据时间跨度较长(例如:发单与接单时间跨度最长一周之久)
- 数据源格式不定 (例如:binlog数据和业务日志的join)
- join规则多样化
- 系统要求吞吐量大(订单表流量是5M/s) 、延迟低(秒级)
分析
显然根据窗口实现是不可取的,首先多流之间跨度较大,窗口无法支持时间跨度这么大的延迟。为此,我们需要一个高效的,具有持久化功能的Cache服务,来缓存先到的流。
并且针对特殊业务,我们需要支持流的保序性。流的保序性是我定义的一个说法(或名词),它指的是如果数据流中存在多张表的数据,而这些表依照一个次序由业务发过来。(如业务数据落到MySQL Binlog,然后可以按照订单id partition到Kafka Topic)我们在下游处理过程和Join的过程中,需要对流中的分表保序。保序要注意的几点是可以按照主键id(订单id)取哈希作为partition key,确保同样主键的数据落到下游同partition的topic,值得注意的一点是,如果Executor端使用了Producer池的话,要确保采用同一个Producer发送。可采取主键id的哈希值对池大小取模的方式来做。
这里保序主要为了确保多流Join时如果有非对等流,即某一个流到达后需要输出它的相关字段,即使没有Join上。(如成单的数据,业务确保了成单状态一定出现在创建订单之前)。
方案
为了解决上述的多流Join问题,进行了如下的方案实现。
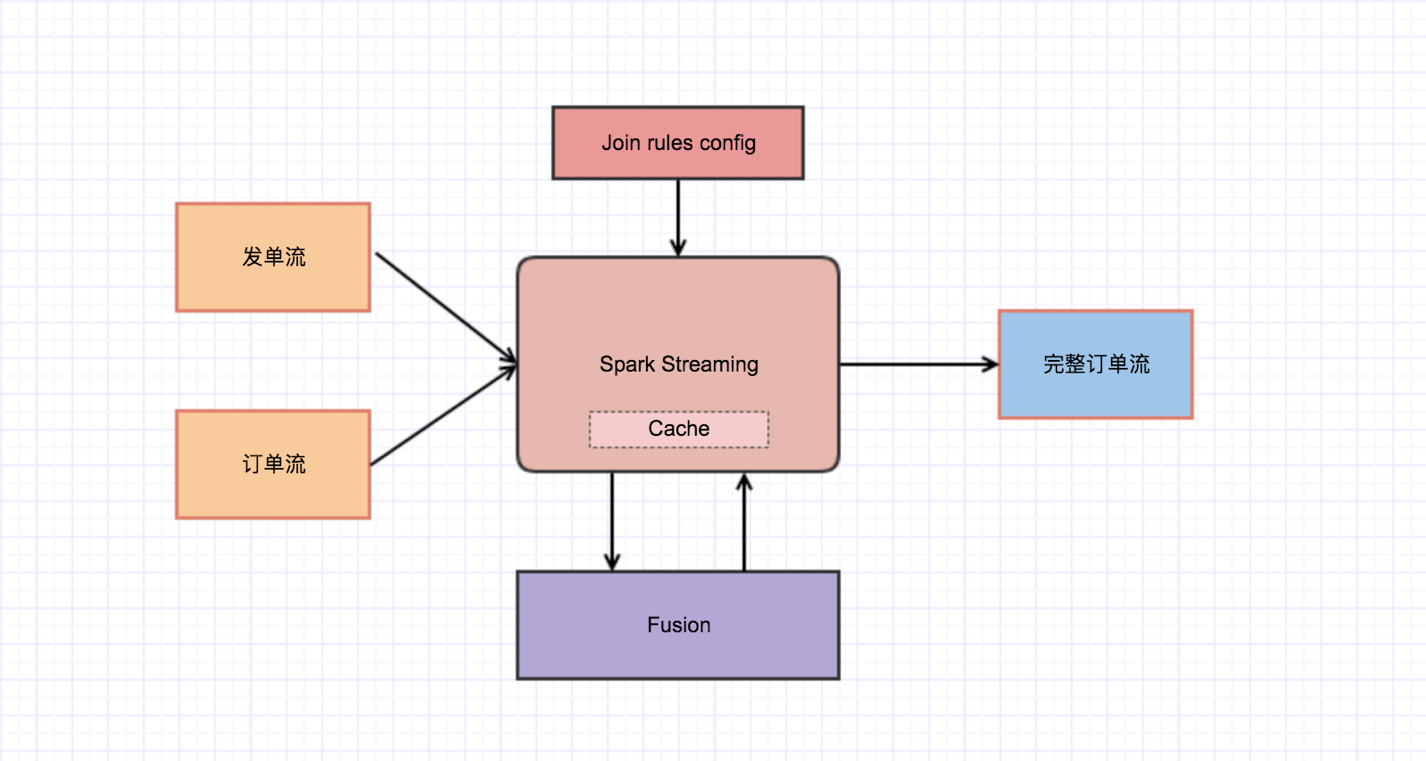
1.通过在Spark Streaming引擎中封装一套Cache服务(可读写外部KV存储,如Fusion、HBase),对先到达的数据流Cache住。2.将各种Join的规则配置化引入引擎,根据Join的场景按需选择规则进行应用。在Join过程中,缓存流在Join上之前一直保持,Join上后进行释放。(这里可能会涉及到KV存储remove操作的性能问题,可进行put的替代或假删)
注:通过引入外部KV存储后,对于作业的延迟或异常问题,也需要关注KV存储(如Fusion、HBase)的集群运行情况。
本人系作者原创,欢迎Spark、Flink等大数据技术方面的探讨。
ps:公众号已正式接入图灵机器人,快去和我聊聊吧。

本文系本人个人公众号「梦回少年」原创发布,扫一扫加关注。