
【Spark】Spark2.x Structured Streaming流式计算介绍
本文主要介绍Spark2.x Structured Streaming流式计算。
目录:
1-引言
随着大数据生态的不断完善,大数据技术的不断发展,基于传统的Map-Reduce计算模型的批处理框架在某些特定场景下的能力发挥越发捉襟见肘。比如说在对实时性要求较高的场景,如实时的用户行为分析,用户推荐等,因此诞生了如samza、storm这样的流式、实时计算框架。而Spark 由于其内部优秀的调度机制、快速的分布式计算能力,以及快速迭代计算的能力使得Spark 能够在某些程度上进行实时处理,Spark Streaming 正是构建在spark之上的流式框架,如下图。
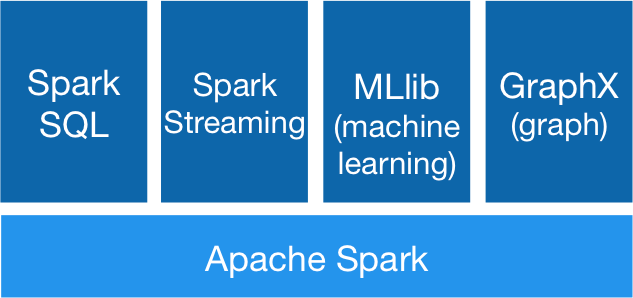
而在spark2.x以后,spark引入了新式的流计算框架——Structured Streaming,它是基于Spark SQL的,同样见下图,可以发现Spark SQL也是构建与Spark之上的,与Spark Streaming平行,都是核心的Spark上层框架。
2-spark-streaming
在介绍Structured Streaming之前,得先介绍下Spark Streaming。Spark Streaming 类似于 Apache Storm,用于流式数据的处理。根据官方文档介绍,Spark Streaming 有高吞吐量和容错能力强这两个特点。Spark Streaming 支持的数据输入源很多,例如:Kafka、Flume和 TCP Socket等。数据输入后可以用 Spark 的map、reduce、join、window 等相关算子进行计算。最终可以sink到 HDFS,数据库等。在 Spark Streaming 中,处理数据的单位是一批(一个batch),Spark Streaming 需要设置batch间隔使得数据汇总到一定的量后再进行操作。batch间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
Spark Streaming正是基于batch的数据处理方式,底层用DStream的数据结构描述流式计算,DStream本质上是一个时间序列的RDD,可以理解为batch RDD,即RDD加上batch维度就是DStream。
其流式处理可以用下面这张图形象展示:
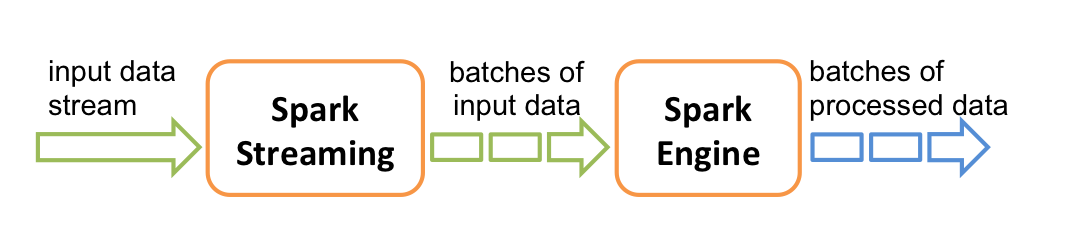
即将输入数据按batch进行处理,每个batch依次处理(各种算子的运算)并输出结果。一个wordcount的典型作业过程如下:
主要核心代码code-1:
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
//构建SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(1))
//获取输入源
val lines = ssc.socketTextStream("localhost", 9999)
//逻辑计算
val wordCounts = lines.flatMap(_.split(""))
.map(word => (word, 1))
.reduceByKey(_ + _)
//输出
wordCounts.print()
//流式计算启动
ssc.start()
ssc.awaitTermination()
其他更复杂的Spark Streaming程序无外乎上述的几个重要步骤,区别和变化可能更多发生在计算的步骤。Spark Streaming有很多流式场景的应用,如ETL、多流join、BI监控数据流join等等。由于本篇文章主要针对新式的Structured Streaming结构化流式计算撰写,所以在此Spark Streaming的具体细节不在展开。
3-structured-streaming
自 Spark 2.x 开始,处理 structured data 的 Dateset/DataFrame 被扩展为同时处理 streaming data,DataFrame/Dataset成为了统一的API。在DataFrame/Dataset的基础上产生了Structured Streaming ,Structured Streaming 以unbounded table为编程模型,满足 end-to-end exactly-once guarantee(端到端的exactly-once保证).下面主要就从DataFrame/DataSet以及end-to-end exactly-once guarantee来展开。
3-1-dataframe-dataset
Structured Streaming顾名思义是结构化流,为什么这么说呢,这是因为Structured Streaming是基于Spark2.x的DataFrame/Dataset API的(Spark Streaming是基于RDD),RDD 是一个一维、只有行概念的数据集,而DataFrame/Dataset是行列的数据集,是一张二维的数据表。RDD与DataFrame/DataSet的对比如下:

DataFrame/Dataset是是一个行列的数据结构,并且具有schema信息,schema信息描述了每行数据的字段和类型信息,如上图Person的name, age, height实际上在schema中描述了,这样每行数据必须依照schema的三列和数据类型的规定。相反RDD[Person]只是一行Person的数据,Person是作为一个整体的,spark框架并不知道Person的具体结构,也就无法进行作业的优化。并且,RDD默认采用的Java序列化方式,序列化结果比较大,并且数据存储在堆存,导致GC比较频繁。而DataFrame/Dataset由于schema信息已经保存,在序列化时就不必带上元数据信息,减少了序列化文件大小,并且数据保存在off heap(堆外内存),大大减少了GC。至于DataFrame和Dataset的区别,实际上在scala中DataFrame就是DataSet[Row]的别名,二者主要区别是Dataset是类型安全的,可以执行编译期检查,而实际二者内存存储是一致的,本质上无差别,可以按需求选择使用并相互转化。(值得注意的一点是scala中DataFrame需要转化为Dataset才可以执行诸如map的算子操作)
因此,Spark2.x最终将流式计算以unbounded table(无界表)形式的结构化数据来呈现(二维表),从而抽象出了统一的API,流式计算无外乎就是静态二维表的无限增长罢了(行列数据随着时间不断增长),如下图所示。自此,DataFrame/Dataset成为了统一的API,同时满足 structured data, streaming data, machine learning, graph等。
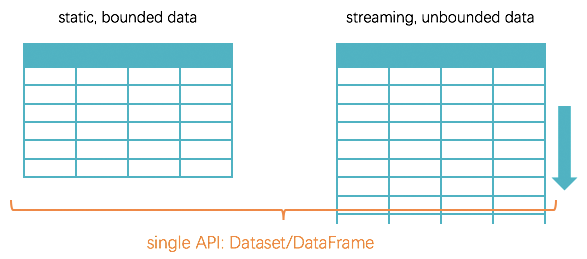
同样是大数据领域经典的wordcount单词计数的例子,这次我们以Structured Streaming实现。(可以与上述Spark Streaming的wordcount例子进行对比)
主要核心代码code-2:
//Spark2.x无需使用SparkConf、SparkContext,而是SparkSession作为统一的切入点
val spark = SparkSession.builder.appName("SocketWordCount").getOrCreate()
//以TCP Socket流构建DataFrame
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
// DataFrame转为Dataset进行算子操作
val words = lines.as[String].flatMap(_.split(" "))
// 产生单词计数,schema字段为value和count
val wordCounts = words.groupBy("value").count()
// 启动Structured Streaming并sink数据到控制台
val query = wordCounts.writeStream.outputMode("complete").format("console").start()
// 等待程序终止
query.awaitTermination()
上述例程对应的流程图如下:
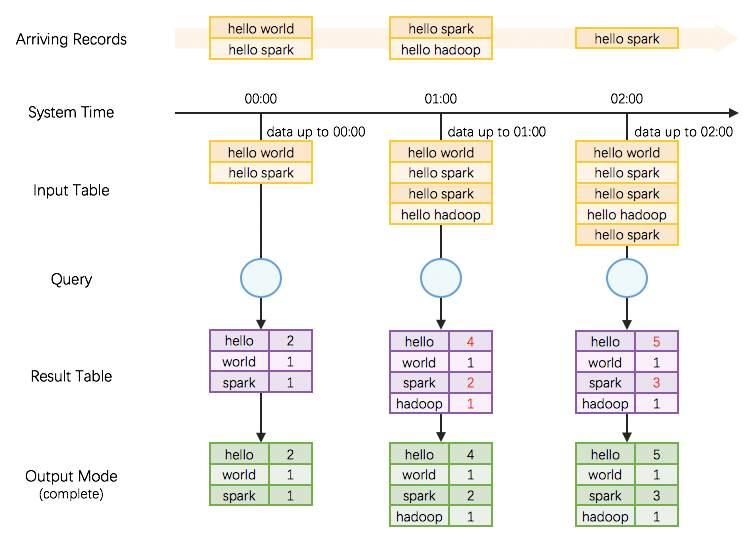
从上图可以很直观的理解unbounded input table的概念,并且注意到在Structured Streaming中batch以trigger interval来控制,如上述例子中是每1min作为一个触发间隔,每一次触发间隔到达,数据被追加到input table作为新行,经过query的处理从而更新result table。Result Table结果表也是一个unbounded table。Result Table更新后我们可以根据需求将数据以complete模式(全部结果表数据)或者update模式(结果表中更新的行数据)sink到外部存储。(hdfs、kafka等)
这里有一个迷惑的点,直观上看Structured Streaming 每次query似乎是对input table的全量数据进行计算。但是在实际执行过程中,由于全量数据会越来越多,那么每次对全量数据进行计算的代价和消耗会越来越大。 Structured Streaming 的做法是:
- 引入全局范围、高可用的 StateStore
- 转全量为增量,即在每次执行时:
- 先从 StateStore 里 restore 出上次执行后的状态
- 然后加入本次input table的新行数据,再进行计算
- 如果有状态改变,将把改变的状态重新 save 到 StateStore 里
所以 Structured Streaming 在编程模型上暴露给用户的是,每次query可以看做面对全量数据,但在具体实现上转换为增量的query(incremental query)。
3-2-end-to-end-exactly-once-guarantee
Structured Streaming保证了端到端的exactly-once,具体来说,端到端在Structured Streaming指的是source-> stream excution -> sink,Structured Streaming 非常显式地提出了输入(Source)、执行(StreamExecution)、输出(Sink)的 3 个组件,也就是说这三个组件并非概念名称而是具体的类或接口,可参见
Github: org/apache/spark/sql/execution/streaming/Source.scala
Github: org/apache/spark/sql/execution/streaming/Sink.scala
并且Structured Streaming 为每个组件显式地做到 fault-tolerant,由此得到整个 streaming 程序的 end-to-end exactly-once guarantees.
注意到e.g.2例子程序中source和sink的过程都有一个format的参数,值是socket,实际上Structured Streaming支持多种source类型,具体参见下述表格:
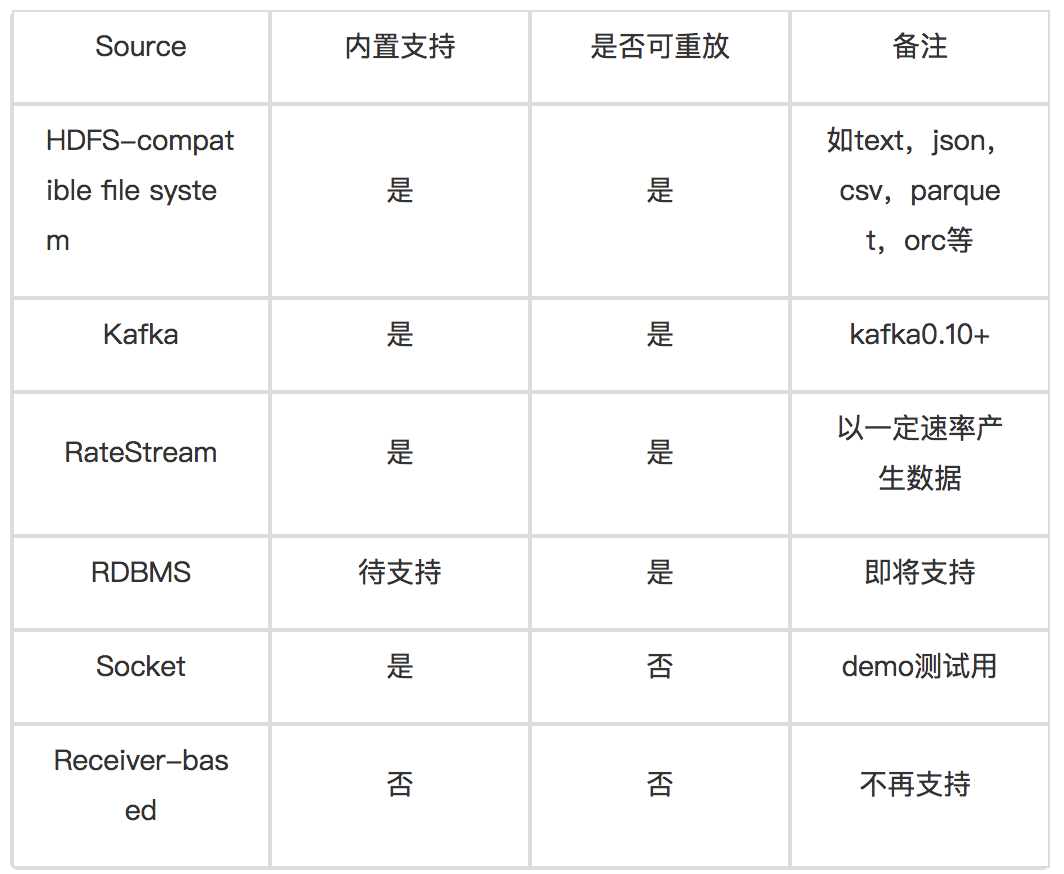
同样的,sink也有多个支持。
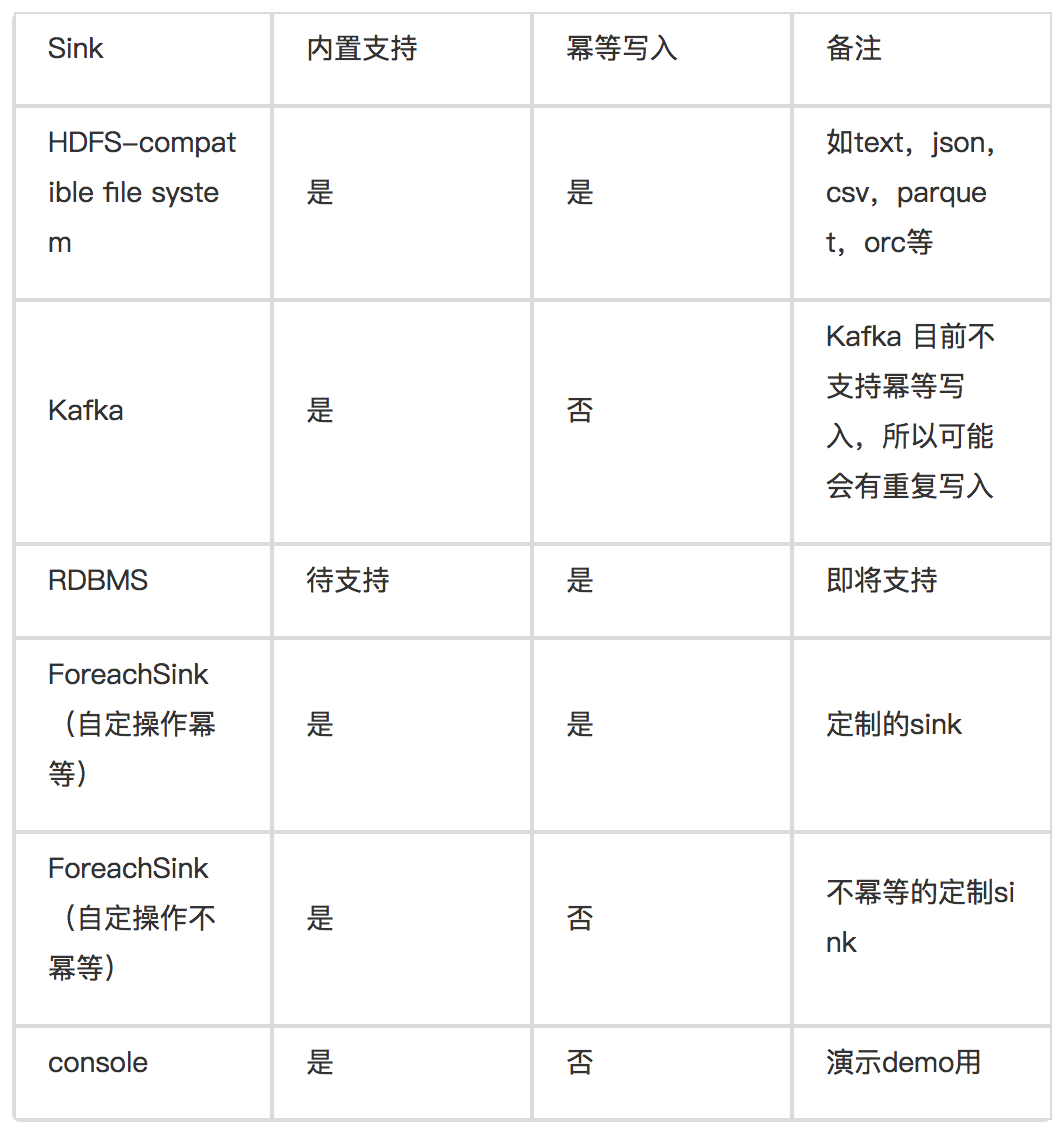
那么,有了source和sink,Structured Streaming是如何确保end-to-end exactly-once的呢?简单来说,offset tracking in WAL + state management + fault-tolerant source and sink = end-to-end exactly-once。offset tracking in WAL是指在source和sink端,执行引擎会把offset持久化到WAL日志中,用作恢复; state management是指全局高可用的StateStore进行的状态管理;fault-tolerant source and sink是指可靠容错的source和sink。
也就是说,如果source选用支持可重放的,如Kafka、HDFS,sink选择支持幂等写入的如HDFS、MySQL,那么Structured Streaming将保证sink中的计算结果是exactly-once的,即确保了end-to-end的exactly-once。
这里重点说一下sink为kafka的情况,实际上在基础平台大数据架构部这边的业务中,我们更多的业务,是从上游的kafka topic到另一个topic,也就是source和sink均为kafka的情况。由于spark本身任务失败会重试,同一个数据可能被写入kafka一次以上。由于kafka目前不支持transactional write,所以多写入的数据不能被撤销,会造成一些重复。当然 kafka 自身的高可用写入(比如写入 broker 了的数据的 ack 消息没有成功送达 producer,导致 producer 重新发送数据时),也有可能造成重复。也就是说,在kafka支持幂等写入之前,可能需要下游实现去重机制。
3-3-structured-streaming-feature
实际上,Structured Streaming相较于Spark Streaming还提供了Event Time、Watermark的支持,具体细节后续文章会陆续呈现,欢迎关注!
4-summary-structured-streaming
总结起来,Structured Streaming相较于Spark Streaming是一个升级版,其最重要的几点变化是
1、DataFrame/Dataset API的替换,性能大幅提升 2、对流式计算模型重新进行了抽象 3、exactly-once的保证
基于这些重要特性的考量,我们这边的业务,如ETL作业,samza移交过来的重构作业,join场景等等的流式作业,未来我们都将采用Structured Streaming方式去实现。
通过业务和实践,发现大多数流式场景数据源是使用kafka,而业务形态是
1、topicA => topicB (ETL作业,普通的join场景)
2、topicA, topicB, … => topicC(多流join的场景)
3、topicA => topicB, topicC, …(topic分流的场景)
这边给出一个实际的例子,需求是按字段对topic分流。
//入口
val sparkSession = SparkSession.builder().appName("按字段topic分流").getOrCreate()
import sparkSession.implicits._
//source
val kafkaDataSets = sparkSession.readStream.format("kafka").option("kafka.bootstrap.servers", consumerBrokersList)
.option("subscribe", consumerTopic)
.option("startingOffsets", "latest")
.option("failOnDataLoss", "false")
.option("maxoffsetspertrigger", "100000")
.load().selectExpr("CAST(value AS STRING)")
.as[String]
//计算逻辑
val result = kafkaDataSets.map(content => {
try {
val flatMap = new JsonFlattener(content).withFlattenMode(FlattenMode.KEEP_ARRAYS).flattenAsMap()
val value = JSON.toJSONString(flatMap, SerializerFeature.PrettyFormat)
var topic = productTopic1
val (classValue, categoryValue) = (flatMap.get("data.type"), flatMap.get("data.neededValue"))
(classValue, categoryValue) match {
case ("app_log", _) => topic = productTopic1
case ("app_event", "needed1") => topic = productTopic2
case ("app_event", "needed2") | ("app_event", "needed3") => topic = productTopic3
case ("app_event", _) => topic = productTopic4
}
(System.currentTimeMillis().toString, topic, value)
} catch {
case e: Exception =>
println("parse error!" + e.getMessage)
null
}
}).filter(_ != null).toDF(List("key", "topic", "value"): _*)
//sink
val sinker = result.writeStream.format("kafka")
.option("kafka.bootstrap.servers", productBrokers)
.option("checkpointLocation", checkpointLocation)
.start()
sinker.awaitTermination()
可以看出,Structured Streaming程序是很直观的,计算主要是DataFrame的应用各种算子进行操纵,并且它是基于Spark SQL,作业会经过catalyst引擎优化,作业执行时间和性能相较于Spark Streaming有了很大提升。
ps:公众号已正式接入图灵机器人,快去和我聊聊吧。

本文系本人个人公众号「梦回少年」原创发布,扫一扫加关注。